Writing a ProxyCommand for SSH
I had this ProxyCommand for SSH that I wrote in Bash and cat, but it didn’t work on my work laptop, which was a Mac. So I wanted to rewrite it in a different language that was more widely supported in default configurations. A native implementation would be great, but I just don’t feel like building and distributing a bunch of different binaries right now. Because of that, now I have to write up this analysis of the possible solutions.
Update: the scripts tested in these experiments are available online: https://github.com/wh0/proxycommand-benchmarks
Availability
I looked up some installation statistics/includion information for a few programming languages that I was considering, on a few platforms I use. While I was at it, I also included some other packages and platforms.
| Package | Debian | Ubuntu [1] | Arch Linux | Git for Windows | macOS |
|---|---|---|---|---|---|
| bash | 99.98% | 99.87% | 100% | yes | no [2] |
| coreutils | 100.00% | 99.88% | 100% | yes | yes [3] |
| perl-base | 100.00% | 99.87% | 100% | yes | yes |
| python-minimal | 98.84% | 99.80% | 99% | no | yes |
| python3-minimal | 71.61% | 7.59% | 99% | no | no |
| nodejs [4] | 15.29% | 0.63% | 60% | no | no |
| netcat-openbsd | 7.77% | 47.68% | 21% | no | yes |
| netcat-traditional | 96.73% | 43.49% | no | no | no |
| openssl | 99.16% | 99.06% | 100% | yes | yes |
| openssh-client | 86.79% | 99.36% | 94% | yes | yes |
| git | 30.04% | 8.09% | 98% | yes | no |
| curl | 12.99% | 20.66% | 100% | yes | yes |
| wget | 99.85% | 99.61% | 89% | no | no |
Notes.
[1] The page says it was last generated in 2016, which is really old.
[2] It has Bash, but it’s an unsuitable build, because it doesn’t have /dev/tcp support.
[3] Not literally GNU Coreutils, but it has a suitable cat.
[4] Node JS isn’t typically packaged by distros, so it might not be accurately reported by these statistics that I got from the distros.
In this comparison, Perl is the most appealing.
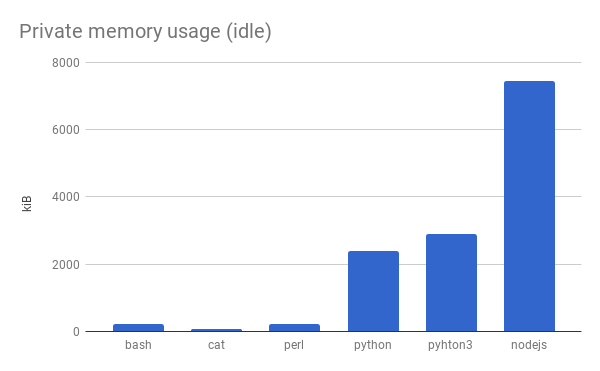
Idle memory usage
I also ran some experiments to measure the memory usage of these interpreters while not doing anything to get a rough sense of how much memory overhead there would be.
Implementation notes.
In order to make sure I measure the memory at the right time, I actually had the interpreters wait.
So it’s only an approximation of idleness.
The interpreters are actually sleeping.
Bash outsources the logic of sleeping for a given amount of time to a separate process.
Shrewd.
Perl has a sleep function built in, while Python needs you to import the time module, so that’s a little unfair.
Node.js uses setTimeout.
In this comparison, Perl is also quite appealing. From here, it looks like Perl vs. Bash + 2×cat could go either way.
Socket memory usage
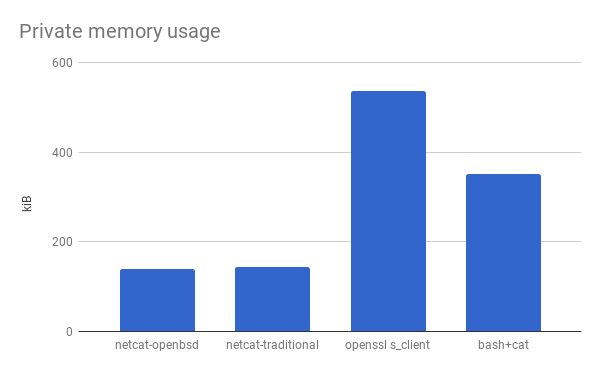
During the main part of my ProxyCommand program, I just need it to forward data verbatim between stdin/out and a socket, like the client-side functionality of netcat. (There’s some stuff it has to do before that, so I can’t just use netcat). These measurements tell us how low the overhead can be at this level of effort.
To start with, I had that implementation in Bash from before.
I simplified it to have only the netcat client functionality, and I measured its memory usage.
I also measured the memory usage of real netcat, just to see how far off it is from a native implementation, and OpenSSL’s s_client command, to see about where an additional layer of encryption would put us.
From the considerations above, I decided to try writing a version in Perl. So I went and learned Perl. Then I measured the memory usage of a version written in Perl.
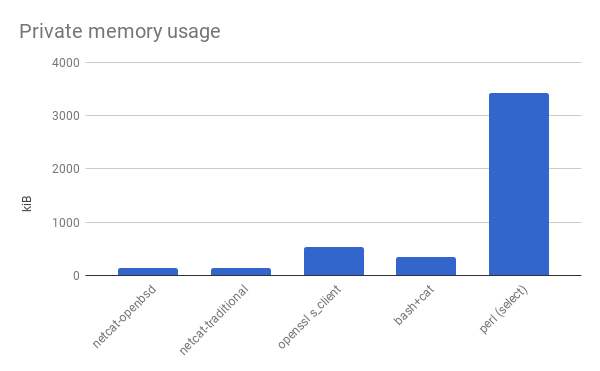
Then I was sad that I spent so long learning Perl only to have written something that used ten times as much memory as a shell script. I wrote a version in Python and compared it, because I thought I would feel better if the Perl version would at least have lower overhead than something else. The Python version was also compatible with Python 3, so I ran that too.
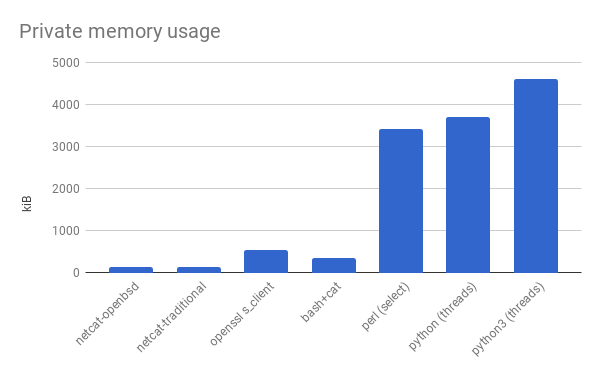
But it wasn’t that satisfying. They’re pretty close. Too close for it to justify the mental anguish of knowing how Perl scalars work. At that point, I started trying to cheat. These were all ProxyCommand programs, logically a small part in a larger system. If I could show that another component used a lot more memory, then Perl would be a pure win in availability and a “don’t care” in memory usage. Maybe the process for SSH itself was large relative to these lowly network routines.
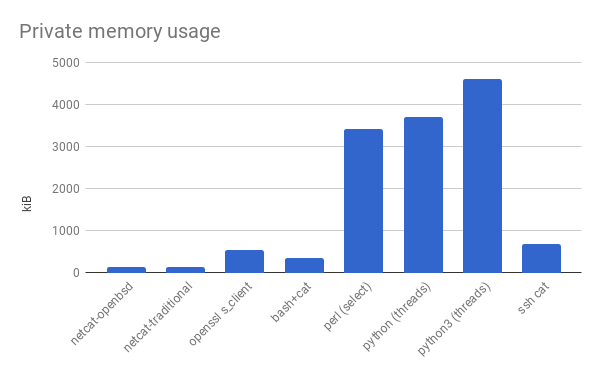
It’s not, though. Well, what else have we got? I’d been looking at command line programs so far. Let’s look at a terminal emulator, which I could reasonably envision myself using in connection with this ProxyCommand program. Surely a GUI program, with all the scrollbars and window decorations would—
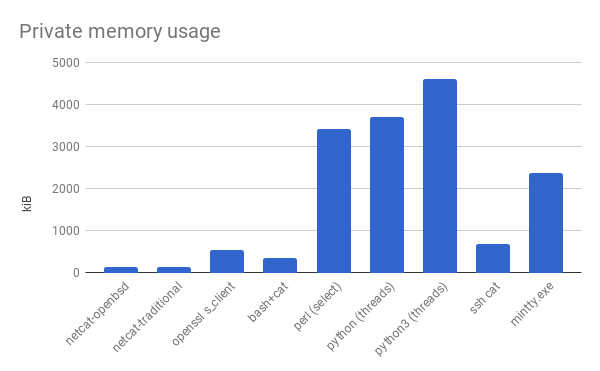
Okay, why does everyone have to make everything so efficient? There’s only one remedy: to benchmark against Node.js.
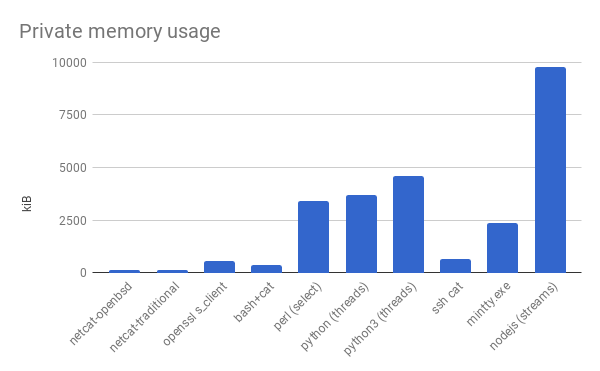
Yup, still easy to pick on Node.js. On a more serious note though, this SSH session is meant to be used as a transport for Git. Here’s the memory usage at an unspecified arbitrary point in time while cloning an unspecified famously large repo from an unspecified famous host, over HTTPS.
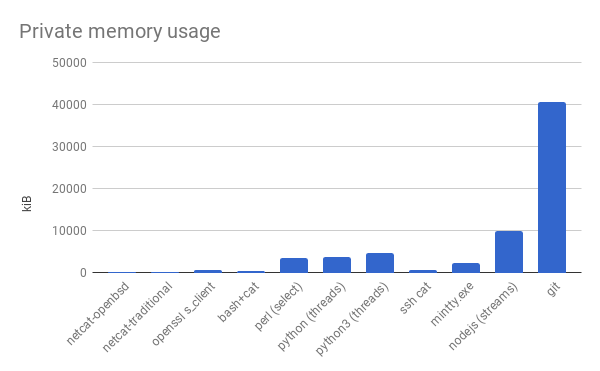
Look how small a few extra megabytes are in the face of a Git clone! (An intentionally large Git clone though.)
Implementation notes. These measurements are done on implementations of my choice, and they don’t all work the same way. The Bash version spawns two subprocesses to copy the two directions, and the subprocesses are counted in the memory usage. The Python version uses two threads to copy the two directions. Perl doesn’t seem to have threads, so its version uses a select loop, and it was very hard to write. The Node.js version uses the streams interface, and it was very easy to write. In cases where I could choose a buffer size, I chose 16 kiB.
Complexity
Here’s how long each socket program was. They’re not particularly golfed.
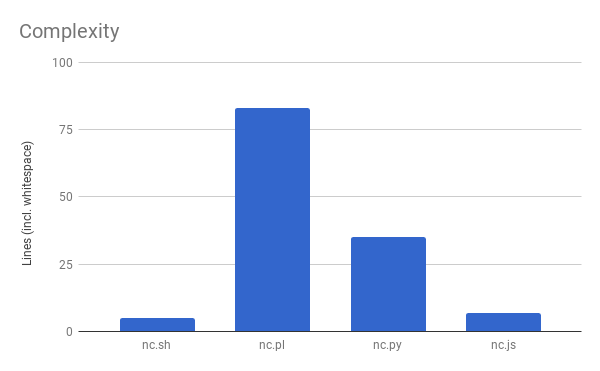
I programmed each one to meet the following requirements:
- Connect to a fixed host (by domain name) on a fixed port.
- Work with IPv4.
- If one side of the stream is blocked (including blocked reads and blocked writes), don’t block the other side.
- Allow each side of the connection to be closed independently.
- Exit when both sides are closed.
Other experiment info
I did most of the memory experiments in a container on Glitch, which uses Ubuntu 16.04 amd64.
Memory usage is measured as the private working set, by subtracting the SHR column from the RES column in top.
Package versions.
| Package | Version |
|---|---|
| bash | 4.3-14ubuntu1.2 |
| coreutils | 8.25-2ubuntu3~16.04 |
| git | 1:2.7.4-0ubuntu1.3 |
| mintty | 2.8.4 (msys2) |
| netcat-openbsd | 1.105-7ubuntu1 |
| netcat-traditional | 1.10-41 |
| nodejs | v8.9.4 (nvm) |
| openssh-client | 1:7.2p2-4ubuntu2.4 |
| openssl | 1.0.2g-1ubuntu4.10 |
| perl | 5.22.1-9ubuntu0.2 |
| python | 2.7.11-1 |
| python3 | 3.5.1-3 |
My last post was about either How long you have to type in all caps before your phone permanently stops suggesting lowercase or Windows disk space requirements. Find out which.